Prompt Complexity and Tiering
GenDB samples from 1.8M DiffusionDB prompts using a heuristic complexity score over nine factors: prompt length, object/attribute counts, compositional density, artist/style attribution patterns, technical rendering and fidelity terminology, explicit detail descriptors, high-level style keywords, color specifications, and interaction or relational expressions. Prompt length and object/attribute counts receive weight 0.2; the remaining seven semantic factors receive weight 0.1. Prompts shorter than 30 characters are removed.
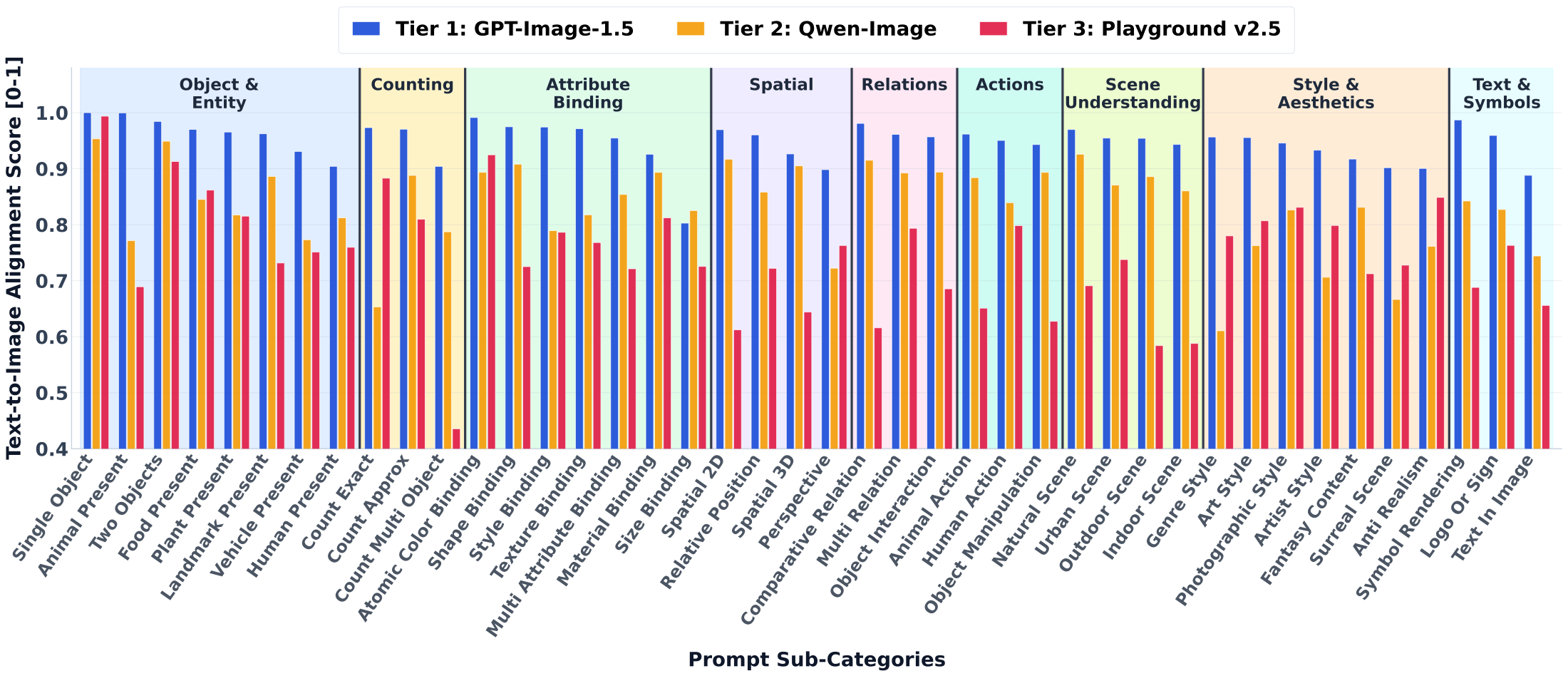
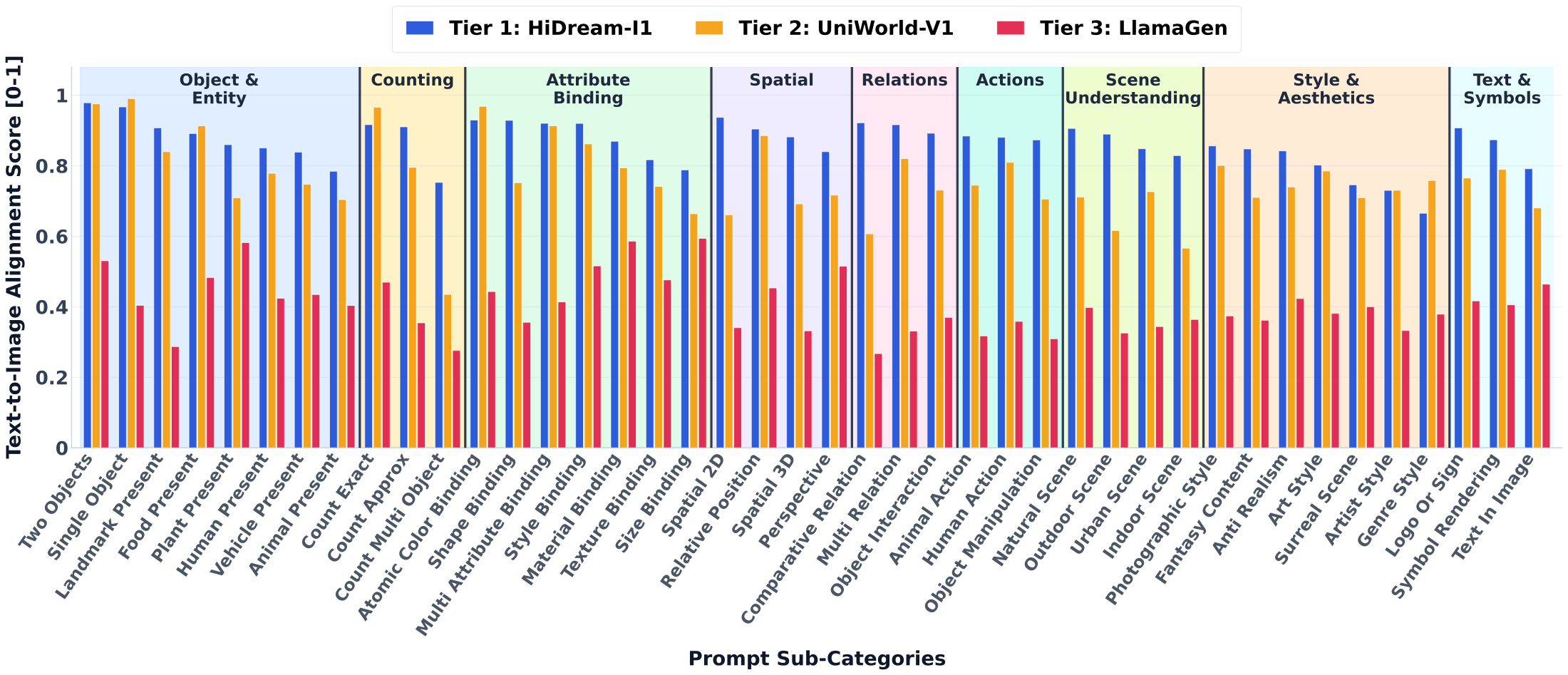
The selected 500K prompts are divided into tiers with \(\tau_1=200\) and \(\tau_2=100\): Tier-1 hard prompts satisfy \(H(p) \ge 200\), Tier-2 medium prompts satisfy \(100 \le H(p) < 200\), and Tier-3 easy prompts fall below 100. Prompts are also categorized into 9 semantic dimensions and 42 subcategories using multi-label category assignment.
| Tier | Representative Prompts |
|---|
| Tier-1 | Long, compositionally rich prompts such as an astronaut-helmet portrait in the style of Norman Rockwell; a detailed office scene with a girl petting a cat; and a cinematic closeup of school friends in a ski cafe with style, fashion, and composition constraints. |
| Tier-2 | Moderate prompts such as futuristic mansion concept art, a puppet-string theater illustration, and a teddy bear in business casual clothing on a couch. |
| Tier-3 | Shorter prompts such as a sad person surrounded by books, a dark painting of a couple looking at each other, and a puffin eating pastry in a diner. |
Representative semantic categories include Object and Entity, Attribute Binding, Counting, Spatial, Relations, Actions, Scene Understanding, Text and Symbols, and Style and Aesthetics. Example subcategories include human present, animal present, atomic color binding, material binding, exact count, 2D spatial relation, object interaction, text in image, logo/sign rendering, fantasy content, and surreal scene.